
指定した列の値をキーにして重複チェックを行い、重複するレコードがなければINSERTし、あればINSERTしない、という処理のSQLを紹介します。
INSERT ON DUPLICATE KEY UPDATE や REPLACE INTO も重複をチェックしたうえでINSERTを実行してくれますが、重複チェックに用いるのはPRIMARY KEY または UNIQUE インデックスが設定されている列を使って重複チェックを行います。
本記事で紹介する方法はPRIMARY KEY または UNIQUE インデックスが設定されていなくても、SQLの中で指定した列を使って重複チェックしてINSERTするか否か判定することができます。
本記事ではMySQLで操作するSQLを紹介しますが、SQLの体裁を少し変えれば他のデータベース用のSQLとして利用することもできると思います。
SQLの説明
まずは図を用いてSQLを説明します。
下記のようなデータ構成で、Item1列とItem2列の組み合わせが一致するレコードがあるかを基に重複チェックを行います。重複がなければINSERTし、重複があればINSERTしません。下記のデータ構成の場合は1行目のレコードはINSERTされず、2行目と3行目のレコードが挿入されることになります。

SQLの処理の流れについて、まずINSERTするデータを基点にItem1、Item2をキーにLEFTJOINを行います。(結合先が見つからないということは同じデータが存在しないということになります。)
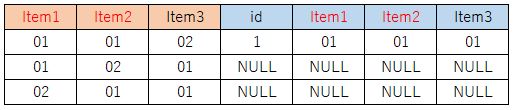
そしてWHERE句で結合先がNULLのデータをピックアップ及びINSERT処理に必要な列をピックアップしテーブルへINSERTを行います。(ここではid列はauto_incrementを指定しているのでINSERT対象列にしていません。)

ちなみに、SELECTした結果をINSERTする構文は下記の記事で確認できます。

SQLの紹介
上記で説明したサンプルの処理を行うSQLを紹介します。
ここで紹介するSQLをそのまま使用して動作確認したい場合、まずはテーブルの用意と既存データを用意する必要があります。下記はサンプルSQLを動かすためのテーブルと既存データを用意するためのSQLとなりますので必要に応じて使用してください。
CREATE TABLE IF NOT EXISTS `test` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`Item1` varchar(50) NOT NULL,
`Item2` varchar(50) NOT NULL,
`Item3` varchar(50) NOT NULL,
PRIMARY KEY (`id`)
);
INSERT INTO `test` (`Item1`, `Item2`, `Item3`) VALUES ( '01', '01', '01');そして下記のSQLが上記のサンプルで説明した仕様のSQLとなります。重複チェックに用いる列をLEFTJOINのON句で指定しています。チェックするデータをUNION句を使ってまとめていますが必ずしもUNION句を使う必要はありません。
INSERT INTO test (Item1, Item2, Item3)
SELECT
CheckData.Item1
,CheckData.Item2
,CheckData.Item3
FROM
(
SELECT "01" Item1, "01" Item2, "02" Item3
UNION
SELECT "01" Item1, "02" Item2, "01" Item3
UNION
SELECT "02" Item1, "01" Item2, "01" Item3
) CheckData
LEFT JOIN test AlreadyData ON
CheckData.Item1 = AlreadyData.Item1 AND
CheckData.Item2 = AlreadyData.Item2
WHERE AlreadyData.Item1 IS NULL以上となります。参考になれば幸いです。

